
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- Java
- 시그모이드
- 인공지능 수학
- 오류역전파
- ncbi
- Kaggle
- COVID
- 블록체인
- RNN
- 생물정보학
- 인공신경망
- 서열정렬
- CNN
- 이항분포
- HMM
- MERS
- bioinformatics
- AP
- 바이오파이썬
- 딥러닝
- BLaST
- SVM
- AP Computer Science A
- 생명정보학
- 자바
- 바이오인포매틱스
- 파이썬
- 결정트리
- 캐글
- 인공지능
- Today
- Total
데이터 과학
KoBERT로 영화 감상 리뷰 분석하기 본문
NSMC 원본 txt 파일을 직접 다운로드해서 KoBERT로 학습하는 파이썬 소스입니다.
설치:
!pip install -q transformers accelerate sentencepiece scikit-learn pandas tqdm
데이터 다운로드:
!wget -q https://raw.githubusercontent.com/e9t/nsmc/master/ratings_train.txt
!wget -q https://raw.githubusercontent.com/e9t/nsmc/master/ratings_test.txt
라이브러리 불러오기:
import pandas as pd
import numpy as np
import torch
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, f1_score
from torch.utils.data import Dataset
from transformers import (
AutoTokenizer,
AutoModelForSequenceClassification,
TrainingArguments,
Trainer
)
데이터 읽어오기
train_df = pd.read_table("ratings_train.txt")
test_df = pd.read_table("ratings_test.txt")
print(train_df.head())
print(test_df.head())
결측치 제거
train_df = train_df.dropna()
test_df = test_df.dropna()
train_df = train_df[["document", "label"]]
test_df = test_df[["document", "label"]]
print(train_df.shape)
print(test_df.shape)
샘플 데이터 만들기 : 데이터 갯수를 좀 줄여야 합니다.
train_df = train_df.sample(10000, random_state=42)
test_df = test_df.sample(2000, random_state=42)
KoBERT 토크나이저 불러오기
model_name = "skt/kobert-base-v1"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(
model_name,
num_labels=2
)
파이토치 데이터 셋 만들기
class NSMCDataset(Dataset):
def __init__(self, dataframe, tokenizer, max_len=128):
self.texts = dataframe["document"].tolist()
self.labels = dataframe["label"].tolist()
self.tokenizer = tokenizer
self.max_len = max_len
def __len__(self):
return len(self.texts)
def __getitem__(self, idx):
text = str(self.texts[idx])
label = int(self.labels[idx])
encoding = self.tokenizer(
text,
truncation=True,
padding="max_length",
max_length=self.max_len,
return_tensors="pt"
)
return {
"input_ids": encoding["input_ids"].squeeze(0),
"attention_mask": encoding["attention_mask"].squeeze(0),
"labels": torch.tensor(label, dtype=torch.long)
}
데이터셋 생성
train_dataset = NSMCDataset(train_df, tokenizer)
test_dataset = NSMCDataset(test_df, tokenizer)
평가함수
def compute_metrics(pred):
labels = pred.label_ids
preds = np.argmax(pred.predictions, axis=1)
acc = accuracy_score(labels, preds)
f1 = f1_score(labels, preds)
return {
"accuracy": acc,
"f1": f1
}
학습 설정
training_args = TrainingArguments(
output_dir="./kobert_nsmc_result",
num_train_epochs=2,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
learning_rate=2e-5,
weight_decay=0.01,
logging_steps=100,
eval_strategy="epoch",
save_strategy="epoch",
load_best_model_at_end=True,
report_to="none"
)
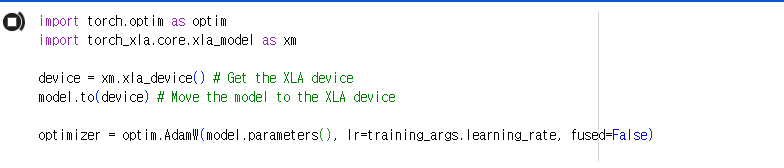
평가
trainer.evaluate()
문장예측
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
def predict_sentiment(text):
model.eval()
inputs = tokenizer(
text,
return_tensors="pt",
truncation=True,
padding="max_length",
max_length=128
)
inputs = {key: value.to(device) for key, value in inputs.items()}
with torch.no_grad():
outputs = model(**inputs)
probs = torch.softmax(outputs.logits, dim=1)
pred = torch.argmax(probs, dim=1).item()
label = "긍정" if pred == 1 else "부정"
confidence = probs[0][pred].item()
return label, confidence
texts = [
"이 영화 정말 재미있고 감동적이었다.",
"스토리가 너무 지루하고 시간이 아까웠다.",
"배우 연기는 좋았지만 전개가 아쉬웠다.",
"완성도는 낮지만 아이디어는 괜찮았다."
]
for text in texts:
label, confidence = predict_sentiment(text)
print(f"{text} → {label}, 확률: {confidence:.4f}")

